Multilingual Text Detoxification (TextDetox) 2025
Stop the war!
Sponsored bySynopsis
- Task: Given a toxic piece of text, re-write it in a non-toxic way while saving the main content as much as possible.
- Input: toxic sentences in 15 languages from all over the globe: English, Spanish, German, Chinese, Arabic, Hindi, Ukrainian, Russian, Amharic, Italian, French, Hebrew, Hinglish, Japanese, and Tatar. [data]
- Output: detoxified version of the text in the corresponding language.
- Evaluation: automatic and manual evaluation based on three parameters: style transfer accuracy; content preservation; fluency.[Github repo]
- Submission: [CodaLab] is now open! Final submissions deadline: May 23
- Registration: [CLEF2025 Registration]
- Contact: [HuggingFace space][google group]
- Paper submission link: [Easychair CLEF2025][Instructions]
- Paper template: [Template]
Task
Identification of toxicity in user texts is an active area of research. Today, social networks such as Facebook, Instagram are trying to address the problem of toxicity. However, they usually simply block such kinds of texts. We suggest a proactive reaction to toxicity from the user. Namely, we aim at presenting a neutral version of a user message which preserves meaningful content. We denote this task as text detoxification.

More text detoxification examples in English:
| Toxic | Detoxified |
|---|---|
| he had steel b*lls too! | he was brave too! |
| delete the page and sh*t up | delete the page |
| what a chicken cr*p excuse for a reason. | what a bad excuse for a reason. |
Languages
In this competition, we suggest you create detoxification systems for various languages from several linguitic families. We have languages from the 2024 edition — English, Spanish, German, Chinese, Arabic, Hindi, Ukrainian, Russian, and Amharic — together with new languages: European languages — Italian, French, Turkic language Tatar, Semitic language Hebrew, Asian language Japanese, and even one very popular code-switch language Hinglish!
Definition of toxiciy
One of the crucial points in this task is to have a common ground on how to estimate if the text is toxic or not. In our task, we will work only with explicit types of toxicity—obvious present of obscene and rude lexicon where still there is meaningful neutral content present—and do not work with implicit types—like sarcasm, passive aggressiveness, or direct hate to some group where no neutral content can be found. Such implicit toxicity types are challenging to be detoxified so the intent will indeed become non-toxic. For this reason, we tried to pick for our datasets the sentences with explicit toxicity where we can detoxify it. However, toxicity can be quite a subjective intent. We hope, that we will agree on the majority of the cases what should be toxic or not. In the end, the main goal is to make the texts and the world at least somehow less toxic ;)
Phases
The shared task will be divided into two phases — development and test. In both phases, we are make the emphasis on cross-lingual and multilingual text detoxification.Development Phase The parallel traning data is available for these languages: English, Spanish, German, Chinese, Arabic, Hindi, Ukrainian, Russian, and Amharic. In our test set, we have 600 toxic sentence per these languages together with 100 toxic sentence for new languages—Italian, French, Hebrew, Hinglish, Japanese, and Tatar! Your task will be to come up with text detoxification models for new languages with no parallel training data as well as aiming to have the best overall multilingual model.
Test Phase We will add even more test toxic sentences for new languages!
Methodology
Supervised Baselines
If a parallel corpus of toxic-neutral pairs is already available, then you can fine-tune any text generation model. You can refer to the ruT5 model for detoxification example from the shared task at the Dialogue Evaluation forum.
We provide one of the top solution from TextDetox2024 mT0-XL-detox and mBART baselines fine-tuned on 9 languages.
The code example how to fine-tune your own seq2seq model is availale as a Google Colab notebook.
Unsupervised Baselines
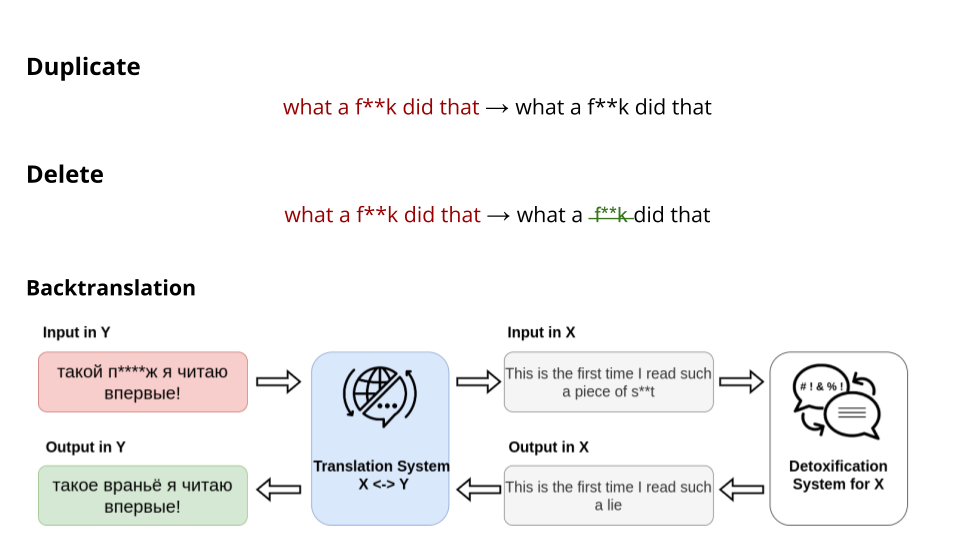
- Duplicate: a simple duplication of the toxic input.
- Delete: elimination of a toxic keywords based on a predifined dictionary for each language.
- Backtranslation: a more sophisticated cross-lingual transfer method. Translate the input to the language for which powerful detoxification model in available, perform detoxification, and translate back to the target language. The translation is done with NLLB-600M model, detoxification with English bart-base-detox model.
- LLMs prompting: for sure, you can utilize any LLMs in zero-shot or few-shot format. As a baseline, we provide zero-shot results of LLaMa-70B as well as GPT-4-0613, GPT-4o-2024-08-06, and o3-mini-2025-01-31 prompting.
Data
Training Data
- Parallel Text Detoxification Dataset The link to the parallel multilingual text detoxification data. This dataset contains 400 pairs for each of 9 languages.
- Toxicity Classification Dataset. To support broader experiments with toxicity, we provide a compilation of toxicity classification data for all 15 languages.
- Toxic Keywords List. Toxic keywords for all 15 languages and toxic spans for 9 languages.
Test Data
The test data for all languages is available [here].
!!!May 8: Test data is updated for the test phase!!!
Evaluation
For the whole competition, the automatic evaluation metrics set will be available. We provide the multilingual automatic evaluation pipeline based on main three parameters:
- Style Transfer Accuracy: Given the generated paraphrase, classify its level of non-toxicity. For this, specifically fine-tuned xlm-roberta-large for toxicity binary classification is used.
- Content preservation: Given two texts, evaluate the similarity of their content. We calculate it as cosine similarity between LaBSe embeddings.
- Fluency: To estimate the adequacy of the text and its similarity to the human-written detoxified references, we use xCOMET model. Based on our experiments, COMET machine translation models showed perfect correlation with the annotation of fluency in detoxified texts.
Each metric component lies in the range [0;1]. To have the one common metric for leaderboard estimation, we will calculate Joint metric as the mean of combination of STA*SIM*FL per sample.

[2025-edition metrics update] As you can compare from 2024 shared task edition, the calculation of J score advanced significantly (see the formula). Thus, in each metrics parameter--STA, SIM, and FL--we take take into account human references. For STA, we check not only the probability of a new output to be a non-toxic sentence, but also if its non-toxicity score is less than human references. This is motivated by the fact that even human detoxifications might be not ideally non-toxic. For SIM, we calculate the weighted sum of output's similarity to the original sentence as well as the human detoxification. Finally, machine-translation inspired FL metric xCOMET evaluates the similarity of the output to the human-written detoxified version.
Automatic Evaluation Code is fully publicly available [here].
Submission
All submissions are handled through Codalab.
To get the submission file for the phase, you need to go to the Participate -> Files page and download Public data. You will receive a .tsv file to fill in. You must fill in all the rows in the file -- either dublicate the toxic input or provide your model output -- and then .zip your .tsv submission.
On the leaderboard, you will see the final J score per all languages. We divide columns of the leaderboard into two categories:
- AvgP: Languages with parallel data (previous 9 languages).
- AvgNP: Languages without available parallel data (new 6 languages).
Also, if you would like to see detialed scores per language and per each metrics parameter, you can download View scoring error log.
Please, follow carefully submissions requirements!
- Your submission must be in .zip format with a .tsv file inside: Make sure that you provide a .tsv file to follow this rule.
- Your submission must contain three columns: toxic_text, neutral_text, and lang.
- You must not edit the neutral_text and lang columns: Texts in these columns should correspond to the original inputs.
- Do not provide NaN in your .tsv file: Please NaNreplace them by, for example, given inputs, as they will break your submission attempt.
- Do not remove lines: Size of your submission should correpospond to the size of an original file.
Important Dates
- Registration to CLEF2025: is now open! Register here and join our Google Group.
- April 25, 2025: Registration closes.
- May 8, 2025: Test phase starts.
- May 23, 2025: Test phase ends, final submissions.
- May 30, 2025: Participants paper submission.
- June 27, 2025: Notification of acceptance.
- July 7, 2025: Camera-ready due.
- September 9-12, 2025: CLEF Conference in Madrid, Spain!
Results: LLM-as-a-Judge
27th June: Additionally to the main automatic leaderboard, we provide the evaluation results with LLM-as-a-Judge: fine-tuned Llama-3.1-8B-Instruct on the manual annotation from TextDetox2024. Please, find below, the results for new languages withour parallel training data for which was the main cross-lingual challenge:| # | User | average | it | ja | he | fr | tt | hin |
|---|---|---|---|---|---|---|---|---|
| 1 | golden annotation | 0.828 | 0.893 | 0.904 | 0.783 | 0.724 | 0.780 | 0.887 |
| 2 | Team ReText.Ai Team | 0.722 | 0.823 | 0.805 | 0.657 | 0.860 | 0.583 | 0.606 |
| 3 | ducanhhbtt | 0.720 | 0.842 | 0.820 | 0.681 | 0.889 | 0.495 | 0.592 |
| 4 | Team Detox | 0.704 | 0.812 | 0.784 | 0.631 | 0.843 | 0.575 | 0.578 |
| 5 | Team MetaDetox | 0.691 | 0.821 | 0.721 | 0.610 | 0.883 | 0.493 | 0.621 |
| 6 | Jiaozipi | 0.688 | 0.795 | 0.787 | 0.611 | 0.850 | 0.541 | 0.544 |
| 7 | Dalfa | 0.678 | 0.789 | 0.703 | 0.615 | 0.790 | 0.621 | 0.548 |
| 8 | Team Transformers | 0.675 | 0.813 | 0.781 | 0.618 | 0.854 | 0.506 | 0.479 |
| 9 | Team cake | 0.674 | 0.791 | 0.796 | 0.581 | 0.853 | 0.436 | 0.584 |
| 10 | sky.Duan | 0.668 | 0.822 | 0.769 | 0.619 | 0.873 | 0.416 | 0.509 |
| 11 | baseline_gpt4 | 0.662 | 0.790 | 0.779 | 0.578 | 0.865 | 0.438 | 0.524 |
| 12 | SVATS | 0.662 | 0.775 | 0.734 | 0.576 | 0.815 | 0.523 | 0.549 |
| 13 | Team The Toxinators 2000 | 0.648 | 0.742 | 0.745 | 0.495 | 0.790 | 0.611 | 0.503 |
| 14 | baseline_mt0 | 0.641 | 0.749 | 0.711 | 0.501 | 0.793 | 0.598 | 0.494 |
| 15 | Team Pratham | 0.639 | 0.752 | 0.710 | 0.495 | 0.801 | 0.575 | 0.502 |
| 16 | shashist | 0.638 | 0.732 | 0.683 | 0.594 | 0.803 | 0.505 | 0.509 |
| 17 | nikita.sushko | 0.628 | 0.763 | 0.722 | 0.573 | 0.807 | 0.492 | 0.410 |
| 18 | danielleee | 0.611 | 0.759 | 0.728 | 0.510 | 0.860 | 0.379 | 0.430 |
| 19 | Penitto | 0.608 | 0.752 | 0.725 | 0.530 | 0.845 | 0.349 | 0.447 |
| 20 | Davv | 0.608 | 0.742 | 0.744 | 0.523 | 0.816 | 0.339 | 0.487 |
| 21 | jrluo | 0.597 | 0.718 | 0.680 | 0.383 | 0.764 | 0.582 | 0.453 |
| 22 | SomethingAwful | 0.579 | 0.728 | 0.643 | 0.490 | 0.814 | 0.324 | 0.477 |
| 23 | Cchenz | 0.560 | 0.709 | 0.631 | 0.510 | 0.736 | 0.403 | 0.366 |
| 24 | baseline_o3mini | 0.559 | 0.748 | 0.661 | 0.497 | 0.826 | 0.209 | 0.411 |
| 25 | Team Nililusu | 0.530 | 0.662 | 0.647 | 0.357 | 0.659 | 0.543 | 0.312 |
| 26 | keke | 0.526 | 0.695 | 0.554 | 0.429 | 0.760 | 0.370 | 0.347 |
| 27 | baseline_gpt4o | 0.526 | 0.697 | 0.680 | 0.370 | 0.718 | 0.327 | 0.363 |
| 28 | baseline_delete | 0.525 | 0.628 | 0.443 | 0.496 | 0.576 | 0.521 | 0.486 |
| 29 | sameertantry | 0.516 | 0.654 | 0.510 | 0.326 | 0.747 | 0.497 | 0.360 |
| 30 | baseline_duplicate | 0.429 | 0.455 | 0.442 | 0.407 | 0.460 | 0.421 | 0.387 |
| 31 | baseline_backtranslation | 0.254 | 0.333 | 0.147 | 0.349 | 0.503 | 0.054 | 0.139 |
| 32 | Dorevain | 0.221 | 0.274 | 0.150 | 0.283 | 0.505 | 0.048 | 0.067 |
As well as languages with the available parallel training data:
| # | User | average | en | es | de | zh | ar | hi | uk | ru | am |
|---|---|---|---|---|---|---|---|---|---|---|---|
| 1 | golden annotation | 0.820 | 0.846 | 0.783 | 0.930 | 0.716 | 0.838 | 0.888 | 0.807 | 0.828 | 0.742 |
| 2 | Team MetaDetox | 0.812 | 0.893 | 0.823 | 0.919 | 0.813 | 0.826 | 0.785 | 0.791 | 0.829 | 0.626 |
| 3 | ducanhhbtt | 0.798 | 0.871 | 0.797 | 0.919 | 0.796 | 0.814 | 0.762 | 0.785 | 0.827 | 0.614 |
| 4 | Team ReText.Ai Team | 0.775 | 0.794 | 0.765 | 0.888 | 0.783 | 0.790 | 0.773 | 0.791 | 0.792 | 0.597 |
| 5 | Jiaozipi | 0.768 | 0.882 | 0.812 | 0.840 | 0.744 | 0.779 | 0.701 | 0.757 | 0.817 | 0.579 |
| 6 | Team The Toxinators 2000 | 0.768 | 0.842 | 0.758 | 0.828 | 0.715 | 0.788 | 0.759 | 0.766 | 0.818 | 0.638 |
| 7 | Team Pratham | 0.768 | 0.843 | 0.763 | 0.822 | 0.717 | 0.793 | 0.758 | 0.782 | 0.811 | 0.621 |
| 8 | baseline_mt0 | 0.768 | 0.843 | 0.764 | 0.825 | 0.717 | 0.791 | 0.751 | 0.770 | 0.809 | 0.639 |
| 9 | sky.Duan | 0.765 | 0.847 | 0.757 | 0.830 | 0.696 | 0.787 | 0.747 | 0.771 | 0.811 | 0.638 |
| 10 | Dalfa | 0.764 | 0.840 | 0.758 | 0.849 | 0.721 | 0.789 | 0.738 | 0.756 | 0.790 | 0.640 |
| 11 | Team cake | 0.742 | 0.805 | 0.807 | 0.866 | 0.652 | 0.720 | 0.689 | 0.757 | 0.792 | 0.591 |
| 12 | jrluo | 0.742 | 0.825 | 0.723 | 0.814 | 0.696 | 0.746 | 0.711 | 0.752 | 0.778 | 0.631 |
| 13 | Team Transformers | 0.737 | 0.871 | 0.778 | 0.853 | 0.673 | 0.713 | 0.706 | 0.758 | 0.788 | 0.492 |
| 14 | nikita.sushko | 0.735 | 0.858 | 0.740 | 0.828 | 0.702 | 0.652 | 0.732 | 0.772 | 0.835 | 0.491 |
| 15 | SVATS | 0.723 | 0.830 | 0.749 | 0.854 | 0.776 | 0.705 | 0.672 | 0.743 | 0.798 | 0.380 |
| 16 | Team Detox | 0.722 | 0.691 | 0.757 | 0.819 | 0.699 | 0.718 | 0.701 | 0.742 | 0.792 | 0.580 |
| 17 | baseline_gpt4 | 0.715 | 0.858 | 0.800 | 0.807 | 0.654 | 0.686 | 0.647 | 0.723 | 0.778 | 0.482 |
| 18 | Team Nililusu | 0.714 | 0.796 | 0.624 | 0.772 | 0.725 | 0.718 | 0.716 | 0.727 | 0.760 | 0.594 |
| 19 | Penitto | 0.694 | 0.837 | 0.756 | 0.831 | 0.685 | 0.643 | 0.638 | 0.643 | 0.762 | 0.452 |
| 20 | Davv | 0.692 | 0.857 | 0.751 | 0.791 | 0.703 | 0.604 | 0.656 | 0.611 | 0.722 | 0.531 |
| 21 | shashist | 0.687 | 0.793 | 0.727 | 0.742 | 0.641 | 0.643 | 0.695 | 0.735 | 0.770 | 0.437 |
| 22 | danielleee | 0.684 | 0.860 | 0.775 | 0.811 | 0.768 | 0.628 | 0.576 | 0.632 | 0.706 | 0.402 |
| 23 | sameertantry | 0.680 | 0.783 | 0.650 | 0.736 | 0.649 | 0.708 | 0.677 | 0.720 | 0.707 | 0.486 |
| 24 | baseline_o3mini | 0.676 | 0.893 | 0.796 | 0.747 | 0.652 | 0.595 | 0.609 | 0.663 | 0.711 | 0.421 |
| 25 | SomethingAwful | 0.663 | 0.856 | 0.763 | 0.749 | 0.629 | 0.592 | 0.631 | 0.694 | 0.685 | 0.367 |
| 26 | Cchenz | 0.607 | 0.828 | 0.710 | 0.724 | 0.579 | 0.530 | 0.504 | 0.559 | 0.631 | 0.401 |
| 27 | baseline_gpt4o | 0.580 | 0.770 | 0.694 | 0.533 | 0.482 | 0.539 | 0.490 | 0.608 | 0.615 | 0.486 |
| 28 | keke | 0.573 | 0.816 | 0.693 | 0.670 | 0.544 | 0.443 | 0.464 | 0.512 | 0.612 | 0.405 |
| 29 | baseline_delete | 0.558 | 0.453 | 0.543 | 0.564 | 0.630 | 0.610 | 0.566 | 0.577 | 0.583 | 0.499 |
| 30 | baseline_backtranslation | 0.458 | 0.743 | 0.466 | 0.479 | 0.231 | 0.442 | 0.395 | 0.256 | 0.689 | 0.425 |
| 31 | baseline_duplicate | 0.432 | 0.370 | 0.451 | 0.479 | 0.429 | 0.446 | 0.432 | 0.455 | 0.450 | 0.380 |
| 32 | Dorevain | 0.346 | 0.838 | 0.407 | 0.417 | 0.170 | 0.337 | 0.288 | 0.152 | 0.201 | 0.305 |
Related Work
- Dementieva D. et al. Methods for Detoxification of Texts for the Russian Language. Multimodal Technologies and Interaction 5, 2021. [pdf]
- Dale D. et. al. Text Detoxification using Large Pre-trained Neural Models. EMNLP, 2021. [pdf]
- Logacheva V. et al. ParaDetox: Detoxification with Parallel Data. ACL, 2022. [pdf]
- Dementieva D. et al. RUSSE-2022: Findings of the First Russian Detoxification Shared Task Based on Parallel Corpora. Dialogue, 2022. [pdf]
- Logacheva, V. et al. A Study on Manual and Automatic Evaluation for Text Style Transfer: The Case of Detoxification. HumEval, 2022. [pdf]
- Dementieva, D. et al. Exploring Methods for Cross-lingual Text Style Transfer: The Case of Text Detoxification. AACL, 2023. [pdf]
- Dementieva, D. et al. Overview of the multilingual text detoxification task at pan 2024. CLEF, 2024. [pdf]
- Dementieva, D. et al. Multilingual and Explainable Text Detoxification with Parallel Corpora. COLING, 2025. [pdf]
Contributors
We have a very big international team working on this Shared Task preparation. The following researchers are contributing to the parallel data preparation:- Daryna Dementieva: Ukrainian, English, Russian
- Nikolay Babakov: Ukrainian, Spanish
- Seid Yimam: Amharic
- Abinew Ali Ayele: Amharic
- Ashaf Elnagar: Arabic
- Xintong Wang: Chinese
- Naquee Rizwan: Hindi, Hinglish
- Caroline Brune: French
- Debora Nozza: Italian
- Sotaro Takeshita: Japanese
- Ilseyar Alimova: Tatar
- Chaya Liebeskind: Hebrew
- Natalia Vanetik: Hebrew
- Marina Litvak: Hebrew
- Shehryaar Shah Khan: Hinglish
Vitaly Protasov contributed with new automatic evaluation metrics and leaderboard preparations.











