Multilingual Text Detoxification (TextDetox) 2024
Stop the war!
Sponsored byWe have new 2025 edition of the task!
Synopsis
- Task: Given a toxic piece of text, re-write it in a non-toxic way while saving the main content as much as possible.
- Input: toxic sentences in multiple languages from all over the globe: English, Spanish, German, Chinese, Arabic, Hindi, Ukrainian, Russian, and Amharic. [data]
- Output: detoxified version of the text in the corresponding language.
- Evaluation: automatic and manual evaluation based on three parameters:style transfer accuracy;content preservation;fluency.[baselines][leaderboard]
- Submission: Codalab as a file submission (and tira.io as an additional option).
- Registration: [CLEF registration]
- Contact: [HuggingFace space][google group]
- Paper submission link: [easychair-clef2024]
- Paper template: [Overleaf Template][template.zip] (up to 8 pages of the main content and unlimited references and appendix)
Task
Identification of toxicity in user texts is an active area of research. Today, social networks such as Facebook, Instagram are trying to address the problem of toxicity. However, they usually simply block such kinds of texts. We suggest a proactive reaction to toxicity from the user. Namely, we aim at presenting a neutral version of a user message which preserves meaningful content. We denote this task as text detoxification.

More text detoxification examples in English:
| Toxic | Detoxified |
|---|---|
| he had steel b*lls too! | he was brave too! |
| delete the page and sh*t up | delete the page |
| what a chicken cr*p excuse for a reason. | what a bad excuse for a reason. |
In this competition, we suggest you create detoxification systems for 9 languages from several linguitic families: English, Spanish, German, Chinese, Arabic, Hindi, Ukrainian, Russian, and Amharic. However, the availability of training corpora will differ between the languages. For English and Russian, the parallel corpora of several thousand toxic-detoxified pairsare available. So, you can fine-tune text generation models on them. For other languages, for the dev phase, no such corpora will be provided. The main challenge of this competition will be to perform an unsupervised and cross-lingual detoxification.
Methodology
Unsupervised Methods
For the majority of the cases and languages, there is not parallel corpus for the detoxification task. For this reason, we create our competition to recreate the real-life conditions. Some examples of stong unserpvised methods:
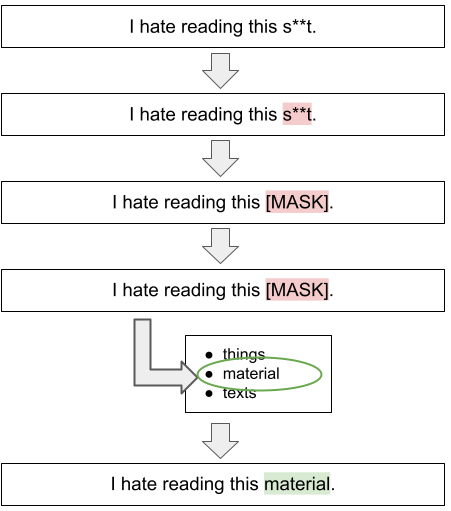
- CondBERT [2,3]: using Masked Language Modeling, mask toxic words in a sentence and rerank the candidates from LM based on their non-toxicity scores.
- ParaGedi [3]: the detoxification task is viewed as paraphrasing task, but during the generation step toxicity scores of the next token prediction are also taken into account.
For the case, where for some language a detoxification corpus or/and model are available, you can use such methods as Backtranslation, Translation of the training corpus to the target language, or Adapter layers. Please, refer to [6] for the detailed explanations of the suggested ideas of cross-lingual detoxification knowledge transfer.
Supervised Methods
If a parallel corpus of toxic-neutral pairs is already available, then you can fine-tune any text generation model. You can refer to the ruT5 model for detoxification example from the shared task at the Dialogue Evaluation forum.
Baselines
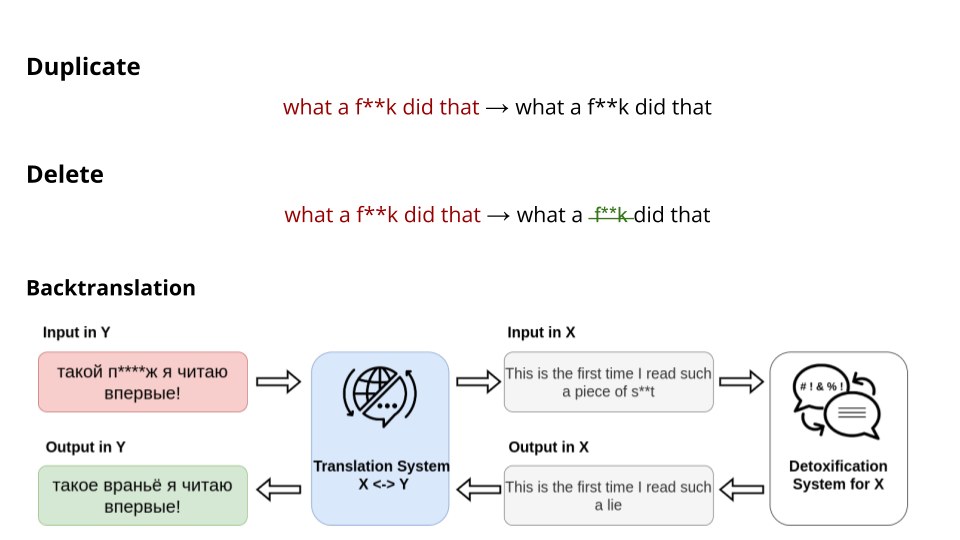
- Duplicate: a simple duplication of the toxic input.
- Delete: elimination of a toxic keywords based on a predifined dictionary for each language.
- Backtranslation: a more sophisticated cross-lingual transfer method. Translate the input to the language for which powerful detoxification model in available, perform detoxification, and translate back to the target language. The translation is done with NLLB-600M model, detoxification with English bart-base-detox model.
For the test phase, we have released a new supervised baseline! The mt5 was fine-tuned on the parallel dev set. The fine-tuned instance can be found here.
Data
For the fine-tuning, ParaDetox datasets for English and Russian are already available. Please, refer to [1] and [5] about more details of the corpora collection. For each language, we have prepared 1k parallel pairs and divided into devand test. The parts will be released according the shared task schedule.
!!!Test phase has started!!!
Parallel Devset is now available! The link to the parallel multilingual data. This dataset contains 400 pairs for each of 9 languages.
Test set can be found here . You are provided with 600 toxic sentences for each language.
Definition of toxiciy
One of the crucial points in this task is to have a common ground on how to estimate if the text is toxic or not. In our task, we will work only with explicit types of toxicity—obvious present of obscene and rude lexicon where still there is meaningful neutral content present—and do not work with implicit types—like sarcasm, passive aggressiveness, or direct hate to some group where no neutral content can be found. Such implicit toxicity types are challenging to be detoxified so the intent will indeed become non-toxic. For this reason, we tried to pick for our datasets the sentences with explicit toxicity where we can detoxify it. However, toxicity can be quite a subjective intent. We hope, that we will agree on the majority of the cases what should be toxic or not. In the end, the main goal is to make the texts and the world at least somehow less toxic ;)
Evaluation
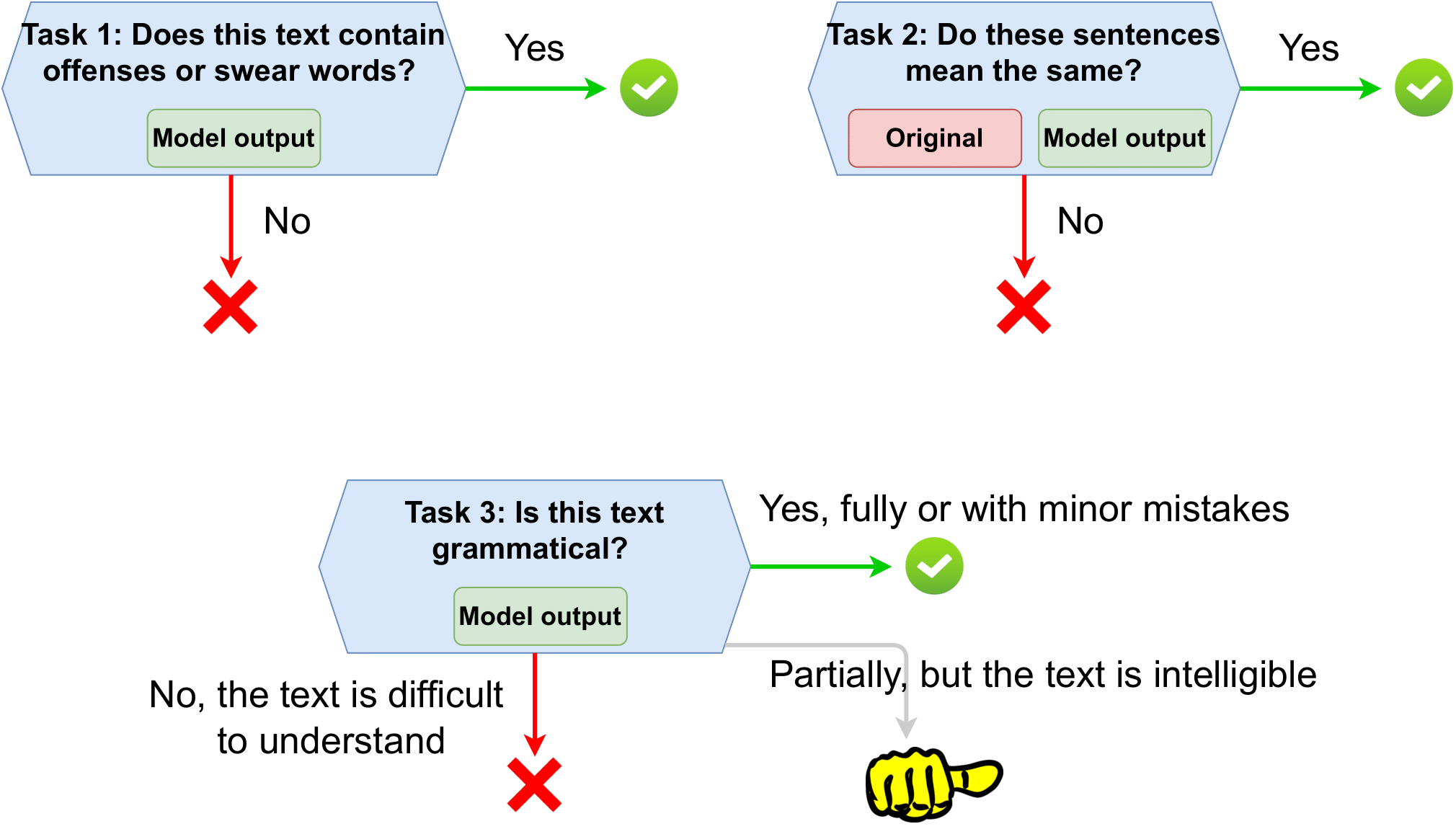
Development Phase
For the whole competition, the automatic evaluation metrics set will be available. We provide the multilingual automatic evaluation pipeline based on main three parameters:
- Style Transfer Accuracy: Given the generated paraphrase, classify its level of non-toxicity. For this, specifically fine-tuned xlm-roberta-large for toxicity binary classification is used. For additional experiments, we also provide the base fine-tuned version of the classifier.
- Content preservation: Given two texts, evaluate the similarity of their content. We calculate it as cosine similarity between LaBSe embeddings.
- Fluency: To estimate the adequacy of the text and its similarity to the human-written detoxified references, we calculate ChrF measure.
Each metric component lies in the range [0;1]. To have the one common metric for leaderboard estimation, we will calculate Joint metric as the mean of STA*SIM*FL per sample.
All scripts for these metrics calculation can be found here.
Test Phase
Even if we already have powerful models to classify texts and embed their meanings, the human judgement is still the best for the final decision [5]. So, for the test set, we will perform both manual and automatic evaluation. For manual evaluation, we will create annotation tasks on Toloka.ai platform corresponding to the same parameters described above. The final leaderboard will be built based on manual evaluation results.
Submission
All submissions are handled through Codalab. We accept solutions submissions. Please follow instructions the corresponding instructions.
Results
Test Phase: Automatic Evaluation Results
Here, we provide the results of automatic evaluation. The main leaderboard is based on the average of J scores per each language. We highlight top3 results per each column.| # | User | average | en | es | de | zh | ar | hi | uk | ru | am |
|---|---|---|---|---|---|---|---|---|---|---|---|
| 1 | Team SmurfCat | 0.523 | 0.602 | 0.562 | 0.678 | 0.178 | 0.626 | 0.355 | 0.692 | 0.634 | 0.378 |
| 2 | lmeribal | 0.515 | 0.593 | 0.555 | 0.669 | 0.165 | 0.617 | 0.352 | 0.686 | 0.628 | 0.374 |
| 3 | nikita.sushko | 0.465 | 0.553 | 0.480 | 0.592 | 0.176 | 0.575 | 0.241 | 0.668 | 0.570 | 0.328 |
| 4 | VitalyProtasov | 0.445 | 0.531 | 0.472 | 0.502 | 0.175 | 0.523 | 0.320 | 0.629 | 0.542 | 0.311 |
| 5 | erehulka | 0.435 | 0.543 | 0.497 | 0.575 | 0.160 | 0.536 | 0.185 | 0.602 | 0.529 | 0.287 |
| 6 | SomethingAwful | 0.431 | 0.522 | 0.475 | 0.551 | 0.147 | 0.514 | 0.269 | 0.584 | 0.516 | 0.299 |
| 7 | mareksuppa | 0.424 | 0.537 | 0.492 | 0.577 | 0.156 | 0.547 | 0.181 | 0.615 | 0.540 | 0.173 |
| 8 | kofeinix | 0.395 | 0.497 | 0.420 | 0.502 | 0.095 | 0.501 | 0.189 | 0.569 | 0.490 | 0.298 |
| 9 | Yekaterina29 | 0.372 | 0.510 | 0.439 | 0.479 | 0.131 | 0.453 | 0.173 | 0.553 | 0.507 | 0.102 |
| 10 | AlekseevArtem | 0.366 | 0.427 | 0.401 | 0.465 | 0.071 | 0.465 | 0.217 | 0.562 | 0.406 | 0.278 |
| 11 | Team NLPunks | 0.364 | 0.489 | 0.458 | 0.487 | 0.150 | 0.415 | 0.212 | 0.466 | 0.402 | 0.194 |
| 12 | pavelshtykov | 0.364 | 0.489 | 0.458 | 0.487 | 0.150 | 0.415 | 0.212 | 0.466 | 0.402 | 0.194 |
| 13 | gleb.shnshn | 0.359 | 0.462 | 0.437 | 0.464 | 0.155 | 0.415 | 0.244 | 0.460 | 0.445 | 0.147 |
| 14 | Volodimirich | 0.342 | 0.472 | 0.410 | 0.388 | 0.095 | 0.431 | 0.181 | 0.483 | 0.452 | 0.169 |
| 15 | ansafronov | 0.340 | 0.506 | 0.319 | 0.362 | 0.178 | 0.456 | 0.133 | 0.328 | 0.507 | 0.270 |
| 16 | MOOsipenko | 0.326 | 0.411 | 0.352 | 0.326 | 0.067 | 0.442 | 0.104 | 0.474 | 0.507 | 0.252 |
| 17 | mkrisnai | 0.324 | 0.475 | 0.422 | 0.396 | 0.109 | 0.270 | 0.194 | 0.460 | 0.383 | 0.205 |
| 18 | Team MarSanAI | 0.316 | 0.504 | 0.305 | 0.315 | 0.069 | 0.456 | 0.105 | 0.315 | 0.508 | 0.269 |
| 19 | Team nlp_enjoyers | 0.316 | 0.418 | 0.359 | 0.384 | 0.104 | 0.389 | 0.172 | 0.432 | 0.431 | 0.157 |
| 20 | Team cake | 0.316 | 0.408 | 0.361 | 0.503 | 0.086 | 0.283 | 0.158 | 0.471 | 0.394 | 0.178 |
| 21 | mT5 | 0.315 | 0.418 | 0.359 | 0.384 | 0.096 | 0.389 | 0.170 | 0.433 | 0.432 | 0.157 |
| 22 | gangopsa | 0.315 | 0.472 | 0.356 | 0.414 | 0.069 | 0.425 | 0.198 | 0.528 | 0.090 | 0.280 |
| 23 | Team SINAI | 0.309 | 0.413 | 0.404 | 0.403 | 0.126 | 0.283 | 0.225 | 0.436 | 0.397 | 0.097 |
| 24 | delete | 0.302 | 0.447 | 0.319 | 0.362 | 0.175 | 0.456 | 0.105 | 0.328 | 0.255 | 0.270 |
| 25 | Team Iron Autobots | 0.288 | 0.345 | 0.351 | 0.364 | 0.124 | 0.373 | 0.204 | 0.404 | 0.367 | 0.058 |
| 26 | LanaKlitotekhnis | 0.253 | 0.460 | 0.161 | 0.298 | 0.062 | 0.274 | 0.110 | 0.341 | 0.384 | 0.184 |
| 27 | Anastasia1706 | 0.242 | 0.349 | 0.271 | 0.191 | 0.064 | 0.404 | 0.088 | 0.334 | 0.248 | 0.227 |
| 28 | ZhongyuLuo | 0.240 | 0.506 | 0.330 | 0.024 | 0.052 | 0.225 | 0.138 | 0.284 | 0.507 | 0.096 |
| 29 | cocount | 0.210 | 0.271 | 0.265 | 0.320 | 0.100 | 0.315 | 0.079 | 0.245 | 0.214 | 0.080 |
| 30 | backtranslation | 0.205 | 0.506 | 0.275 | 0.233 | 0.027 | 0.206 | 0.104 | 0.201 | 0.223 | 0.075 |
| 31 | etomoscow | 0.204 | 0.293 | 0.244 | 0.197 | 0.025 | 0.149 | 0.092 | 0.266 | 0.507 | 0.067 |
| 32 | cointegrated | 0.175 | 0.160 | 0.265 | 0.245 | 0.050 | 0.183 | 0.070 | 0.253 | 0.223 | 0.123 |
| 33 | dkenco | 0.163 | 0.183 | 0.090 | 0.287 | 0.069 | 0.294 | 0.035 | 0.032 | 0.265 | 0.217 |
| 34 | FD | 0.144 | 0.061 | 0.189 | 0.166 | 0.069 | 0.294 | 0.035 | 0.215 | 0.048 | 0.217 |
| 35 | duplicate | 0.126 | 0.061 | 0.090 | 0.287 | 0.069 | 0.294 | 0.035 | 0.032 | 0.048 | 0.217 |
Test Phase: Manual Evaluation Final Results
The results of the final evaluation with crowsdsourcing on a random subsample of 100 texts per language:| # | User | average | en | es | de | zh | ar | hi | uk | ru | am |
|---|---|---|---|---|---|---|---|---|---|---|---|
| 0 | Human References | 0.85 | 0.88 | 0.79 | 0.71 | 0.93 | 0.82 | 0.97 | 0.90 | 0.80 | 0.85 |
| 1 | SomethingAwful | 0.77 | 0.86 | 0.83 | 0.89 | 0.53 | 0.74 | 0.86 | 0.69 | 0.84 | 0.71 |
| 3 | Team SmurfCat | 0.74 | 0.83 | 0.73 | 0.70 | 0.60 | 0.82 | 0.68 | 0.84 | 0.76 | 0.71 |
| 4 | VitalyProtasov | 0.72 | 0.69 | 0.81 | 0.77 | 0.49 | 0.79 | 0.87 | 0.67 | 0.73 | 0.68 |
| 5 | nikita.sushko | 0.71 | 0.70 | 0.62 | 0.79 | 0.47 | 0.89 | 0.84 | 0.67 | 0.74 | 0.68 |
| 6 | erehulka | 0.71 | 0.88 | 0.71 | 0.85 | 0.68 | 0.78 | 0.52 | 0.63 | 0.65 | 0.69 |
| 7 | Team NLPunks | 0.69 | 0.84 | 0.76 | 0.78 | 0.60 | 0.69 | 0.78 | 0.63 | 0.51 | 0.56 |
| 8 | mkrisnai | 0.68 | 0.89 | 0.83 | 0.70 | 0.34 | 0.63 | 0.73 | 0.73 | 0.78 | 0.49 |
| 9 | Team cake | 0.65 | 0.91 | 0.77 | 0.77 | 0.84 | 0.44 | 0.34 | 0.50 | 0.71 | 0.61 |
| 10 | Yekaterina29 | 0.64 | 0.75 | 0.63 | 0.74 | 0.30 | 0.70 | 0.66 | 0.65 | 0.70 | 0.60 |
| 11 | Team SINAI | 0.57 | 0.85 | 0.68 | 0.52 | 0.33 | 0.76 | 0.54 | 0.65 | 0.67 | 0.14 |
| 12 | gleb.shnshn | 0.56 | 0.74 | 0.68 | 0.55 | 0.41 | 0.54 | 0.65 | 0.44 | 0.61 | 0.47 |
| 13 | delete | 0.56 | 0.47 | 0.55 | 0.57 | 0.43 | 0.65 | 0.65 | 0.60 | 0.49 | 0.63 |
| 14 | mT5 | 0.54 | 0.68 | 0.47 | 0.64 | 0.43 | 0.63 | 0.60 | 0.42 | 0.40 | 0.61 |
| 15 | Team nlp_enjoyers | 0.52 | 0.67 | 0.42 | 0.55 | 0.23 | 0.56 | 0.67 | 0.42 | 0.50 | 0.70 |
| 16 | Team Iron Autobots | 0.52 | 0.74 | 0.54 | 0.65 | 0.53 | 0.62 | 0.58 | 0.48 | 0.45 | 0.07 |
| 17 | ZhongyuLuo | 0.51 | 0.73 | 0.52 | 0.01 | 0.56 | 0.49 | 0.49 | 0.42 | 0.68 | 0.72 |
| 18 | gangopsa | 0.50 | 0.74 | 0.20 | 0.72 | 0.37 | 0.61 | 0.75 | 0.48 | 0.00 | 0.61 |
| 19 | backtranslation | 0.41 | 0.73 | 0.56 | 0.34 | 0.34 | 0.42 | 0.33 | 0.23 | 0.22 | 0.54 |
| 20 | Team MarSanAI | 0.18 | 0.89 | --- | --- | --- | --- | --- | --- | 0.70 | --- |
| 21 | dkenco | 0.12 | 0.68 | --- | --- | --- | --- | --- | --- | 0.39 | --- |
Important Dates
- February 1, 2024: First data available and run submission opens.
- April 22, 2024: Registration closes.
- May 14, 2024: Run submission deadline and results out.
- May 31, 2024: Participants paper submission.
- July 8, 2024: Camera-ready participant papers submission.
- September 9-12, 2024: CLEF Conference in Grenoble and Touché Workshop.
Related Work
- Dementieva D. et al. Methods for Detoxification of Texts for the Russian Language. Multimodal Technologies and Interaction 5, 2021. [pdf]
- Dale D. et. al. Text Detoxification using Large Pre-trained Neural Models. EMNLP, 2021. [pdf]
- Logacheva V. et al. ParaDetox: Detoxification with Parallel Data. ACL, 2022. [pdf]
- Moskovskiy D. et al. Exploring Cross-lingual Text Detoxification with Large Multilingual Language Models. ACL SRW, 2022. [pdf]
- Dementieva D. et al. RUSSE-2022: Findings of the First Russian Detoxification Shared Task Based on Parallel Corpora. Dialogue, 2022. [pdf]
- Logacheva, V. et al. A Study on Manual and Automatic Evaluation for Text Style Transfer: The Case of Detoxification. HumEval, 2022. [pdf]
- Dementieva, D. et al. Exploring Methods for Cross-lingual Text Style Transfer: The Case of Text Detoxification. AACL, 2023. [pdf]
Contributors
The following researchers contributed to the parallel data preparation:- Daryna Dementieva: Ukrainian, English, Russian
- Daniil Moskovskiy: English, Russian
- Florian Schneider: German
- Nikolay Babakov: Ukrainian, Spanish
- Seid Yimam: Amharic
- Abinew Ali Ayele: Amharic
- Ashaf Elnagar: Arabic
- Xinting Wang: Chinese
- Naquee Rizwan: Hindi










